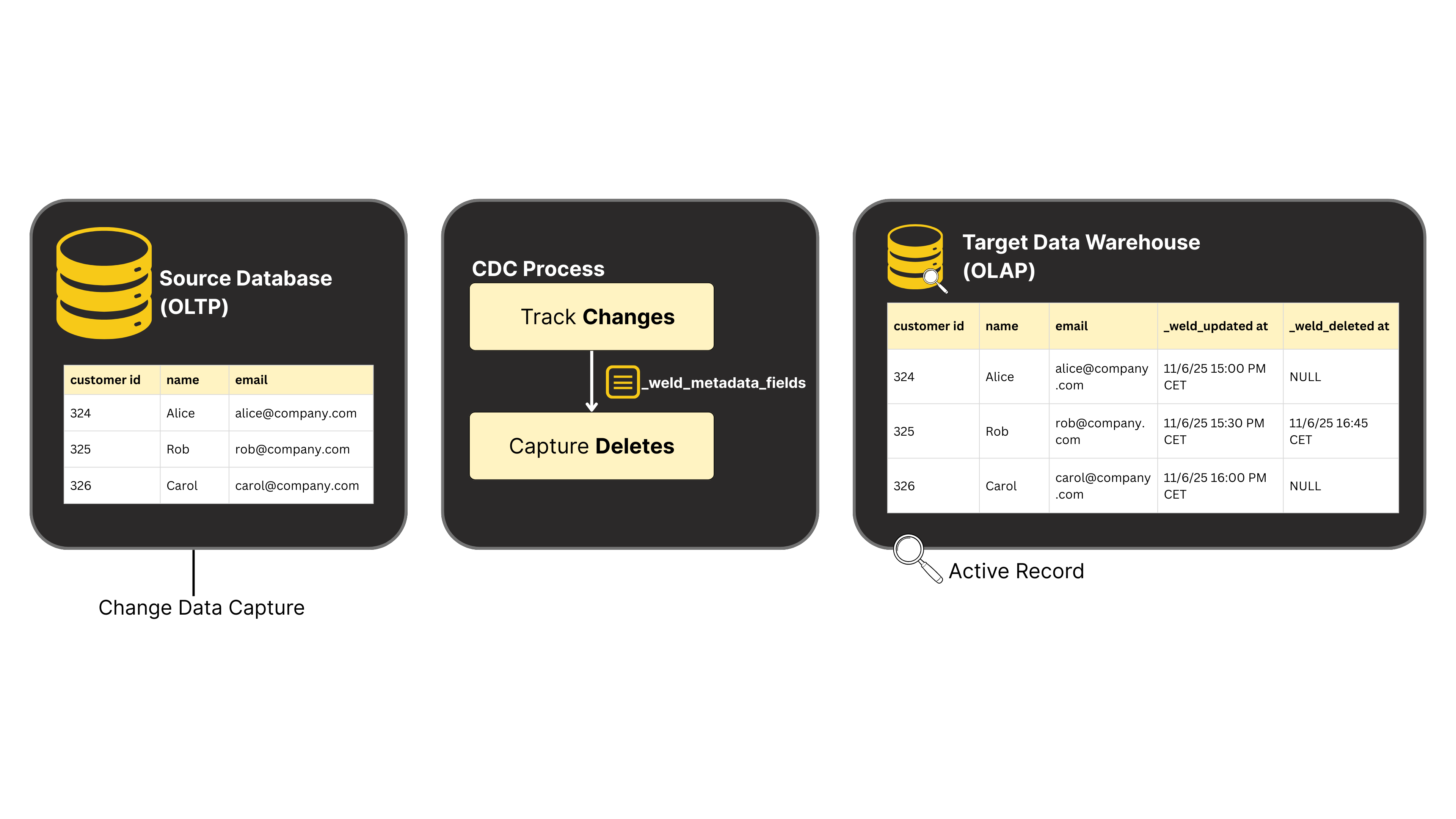
Change Data Capture (CDC)
Change Data Capture (CDC) is a design pattern for continuously identifying inserts, updates, and deletes in a source system and propagating only those changes downstream.
Compared to batch replication, CDC reduces latency, minimizes load on source systems, and helps keep downstream systems consistent as data changes.
When to use CDC
CDC is a good fit when:
- You want near real-time replication (seconds/minutes instead of hours)
- You need reliable deletes and updates (not just new rows)
- You want to reduce load compared to frequent full-table scans on large tables
- You want downstream systems to react faster to operational changes
CDC can be overkill if your datasets are small, change slowly, or a few hours of delay is acceptable.
Common CDC approaches
Different systems implement CDC in different ways. The most common approaches are:
Timestamp or version polling
Query rows where last_modified > last_sync.
- ✅ Simple to set up
- ⚠️ Easy to miss deletes
- ⚠️ Requires careful handling of late updates / clock skew
Snapshot diffs
Take periodic snapshots and compare them.
- ✅ Works in most systems
- ❌ Can get expensive as tables grow
- ⚠️ Latency depends on snapshot frequency
Triggers / outbox tables
Write changes to a change table during writes.
- ✅ Captures inserts/updates/deletes reliably
- ⚠️ Adds write overhead and operational complexity
Log-based CDC
Read from the database’s transaction log or native change stream (e.g. WAL/binlog/change streams).
- ✅ Best coverage for inserts/updates/deletes
- ✅ Strong ordering guarantees
- ✅ Low read load on the source (no table scans)
In most production systems, log-based CDC is preferred when available.
CDC vs other sync modes
| Approach | How it works | Captures deletes | Low latency | Low source load | Best fit |
|---|---|---|---|---|---|
| Full table sync | Re-copy entire tables on a schedule | ❌ | ❌ | ❌ | Small datasets |
| Incremental sync | Pull rows using timestamps or IDs | ⚠️ | ⚠️ | ✅ | Moderate freshness needs |
| Change Data Capture (CDC) | Stream changes from logs/streams | ✅ | ✅ | ✅ | Real-time systems |
How CDC works in Weld (high level)
- Connect your database in Weld using a dedicated user.
- Enable CDC mode for the connector.
- Select tables/collections to capture.
- Weld consumes changes and applies them to your destination based on your latency/apply settings.
Supported databases
Best practices
- Start with a small, high-value domain and expand gradually
- Ensure each replicated table/collection has a stable identifier (primary key or equivalent)
- Make downstream apply logic idempotent (safe on retries)
- Plan for schema changes and backfills
- Monitor freshness/lag, throughput, and errors to avoid silent drift
Housekeeping
If you stop or permanently delete a CDC sync, clean up any CDC-related resources created for that sync (where applicable) to avoid unnecessary retention or overhead.
FAQs
Choosing CDC
Does CDC replace ETL?
Not usually. CDC and batch ETL are complementary:
- Use CDC for continuous freshness (inserts/updates/deletes) and low-latency sync.
- Use batch ETL for initial loads, backfills, historical rebuilds, and recomputing derived models.
A common setup is: snapshot/backfill first, then CDC keeps tables current.
Is CDC always the right choice?
No. CDC adds operational complexity. If your data changes slowly, tables are small, or hourly/daily updates are fine, scheduled syncs can be simpler and cheaper.
What latency should I expect?
CDC is typically seconds to minutes, but depends on source write volume, network, and how changes are applied in the destination (per-event vs micro-batch).
Data correctness
Do I need primary keys (or unique IDs) for CDC?
For reliable updates/deletes, yes.
- Relational tables should have a primary key (or stable unique key).
- MongoDB typically uses
_id.
Without a stable identifier, downstream systems can’t safely apply updates/deletes to the correct record.
Will CDC capture deletes?
With true CDC (log/stream-based), yes. How deletes appear downstream depends on your destination strategy (hard deletes vs soft deletes/flags).
How do schema changes work with CDC?
Adding columns is usually straightforward. Renames/drops/type changes often require coordination and sometimes a backfill. Treat schema evolution as a planned workflow.
Warehouses and apply patterns
How do warehouses apply CDC?
Most destinations apply CDC using one of these patterns:
- Stage → MERGE: land change events in a staging/delta table, then
MERGEinto the target table. - Micro-batch apply: accumulate changes briefly and apply in batches (often better cost/perf).
- Soft delete: represent deletes via a deleted flag/timestamp when physical deletes aren’t desired.
Operations and monitoring
Does CDC impact my production database?
CDC avoids table scans, but it’s not free:
- It reads from a database’s log/stream and may require retaining logs long enough for the consumer to keep up.
- If a CDC sync is paused or abandoned without cleanup, log retention can grow and consume disk.
What should I monitor?
At minimum:
- Replication/apply lag
- Error rate / retries
- Log retention pressure (WAL/binlog/oplog growth)
- Destination apply/merge duration
What happens if Weld goes down or the connection drops?
CDC pipelines typically resume from the last stored position (offset/checkpoint). If the source retention window is exceeded while offline, a resnapshot/backfill may be required.
Can I backfill without breaking CDC?
Yes. Treat backfills as a controlled operation:
- Prefer staging/backfill tables and swap/merge strategies
- Expect higher destination apply cost during large backfills
- Keep CDC running where possible
Database-specific
How does PostgreSQL CDC work?
PostgreSQL CDC is typically WAL-based logical replication, using a replication slot and a publication to define which tables to capture.
See: PostgreSQL CDC
How does MySQL CDC work?
MySQL CDC is typically binlog-based, streaming row changes via a replication connection (commonly binlog_format=ROW).
See: MySQL CDC
How does Microsoft SQL Server CDC work?
SQL Server provides native CDC that reads the transaction log and records changes for enabled tables (commonly via CDC change tables).
See: Microsoft SQL Server CDC
How does MongoDB CDC work?
MongoDB CDC is typically implemented using Change Streams, which emit document-level change events.
See: MongoDB CDC