

ETL vs ELT: What’s the difference and how AI is changing the game
Data integration has evolved significantly since the early days of batch processing and monolithic data warehouses. Central to this evolution are two processes: ETL (extract, transform, load) and ELT (extract, load, transform). Understanding their differences reflects how data infrastructure has adapted to new technologies, especially with the rise of cloud data platforms and AI.
ETL: A legacy born in the era of on-prem
ETL was the standard in the early days of data warehousing. The process involved extracting data from operational systems, transforming it into a usable format, and then loading it into a warehouse. This approach made sense when storage was expensive and compute capacity was limited. Transformation had to happen before the data hit the warehouse because warehouses couldn’t handle much else.
ETL workflows were built for stability and control, often scheduled in overnight batches. However, they were rigid, required heavy engineering, and weren’t designed for real-time insights or iterative analytics.
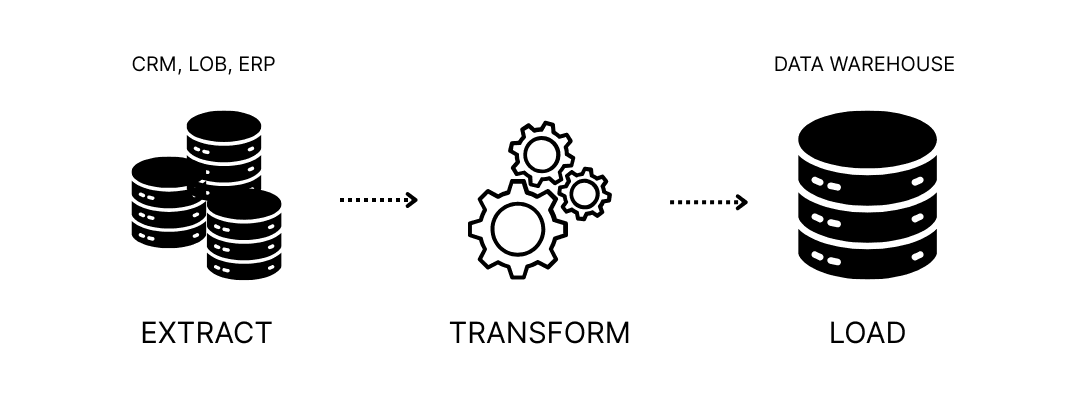
ELT: Built for the cloud
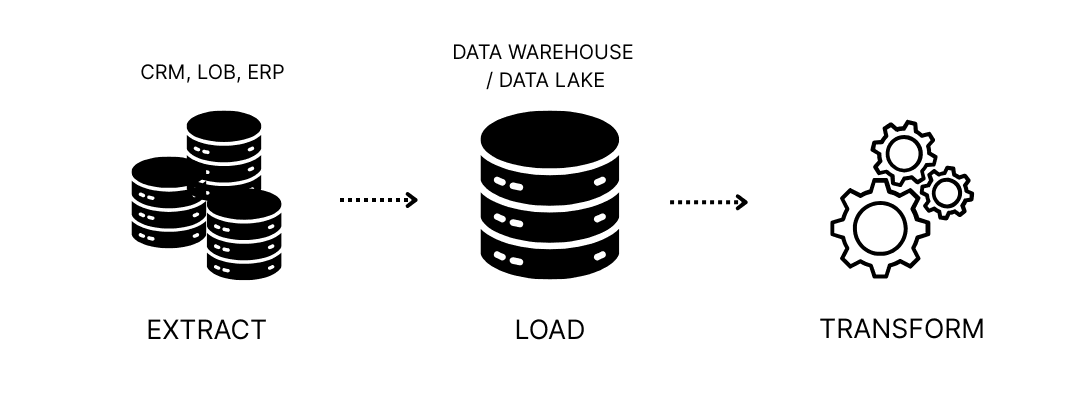
With the rise of cloud data platforms, the game changed. Now, you can extract data, load it raw into your warehouse, and transform it later. That’s ELT.
ELT allows for more flexible workflows, faster time-to-insight, and easier debugging. It also supports modern approaches like reverse ETL and real-time analytics. In short, ELT isn’t just a newer acronym; it’s a more adaptable mindset for working with data at scale.
Real-world applications: When to use ETL or ELT
Understanding the practical applications of ETL and ELT can help determine which approach best suits specific business needs.
ETL in action: Ensuring data compliance and integrity
In industries where data compliance and integrity are paramount, ETL remains a preferred choice. For instance, financial institutions often need to transform data to meet regulatory standards before loading it into their systems. This pre-processing ensures that only compliant data enters the warehouse, maintaining the integrity and reliability of financial reports.
ELT in action: Leveraging cloud scalability for big data
Organizations dealing with massive volumes of data benefit from ELT's ability to leverage cloud scalability. By loading raw data into cloud-based warehouses, businesses can perform complex transformations using the warehouse's processing power. This approach is particularly effective for companies analyzing large datasets to gain insights into customer behavior or market trends.
What AI brings to the table
AI is starting to influence both ETL and ELT, especially ELT given its flexibility and compute-first architecture. Here’s how AI is making an impact:
- Smart transformation logic: AI models can analyze data and suggest or automate transformations, saving hours of manual work.
- Anomaly detection: Machine learning algorithms can flag outliers or errors during ingestion, improving data quality upstream.
- Pipeline optimization: AI can monitor performance and dynamically adjust workflows for efficiency and cost.
- Natural language interfaces: Instead of writing SQL, imagine asking an AI assistant, “Show me the top 5 churn indicators” and getting a cleaned, joined dataset in return.
Blending ETL and ELT: A practical middle ground
In reality, most modern data teams don’t live in a strictly ETL or ELT world. Many use a hybrid approach. You might pre-transform sensitive data before loading it for compliance reasons (ETL), while allowing other datasets to be loaded raw and transformed in-database (ELT) for flexibility and speed.
For example, a company using Weld might extract customer support data and lightly transform it to mask PII before loading it into their data warehouse; an ETL pattern. Meanwhile, product analytics or event data might be streamed directly into the warehouse and transformed there using dbt models or Weld transformations; clearly an ELT setup.
The key is understanding the strengths of each and applying them where they make the most sense. With the right architecture and tooling, you don’t have to pick sides. You can have both governance and agility, compliance and speed.
The future: From ELT to AI-powered data orchestration
We’re moving toward a world where data pipelines are not just automated, but intelligent. AI won’t replace the need for solid data architecture. But it will augment how we design, maintain, and monitor our workflows.
In the future, data teams will spend less time on infrastructure and more time on strategy and experimentation.
As always, the goal is the same: to turn raw data into insights. But the tools we use and the speed at which we can do it, are evolving fast.
References:
- Difference between ELT and ETL – GeeksforGeeks
- AI Data Integration: A Look Into The Future – Astera
- AI in data integration: Types, challenges and key AI techniques – LeewayHertz
- How AI and data integration are shaping the future of data science – Forbes
Further reading
















