What is Change Data Capture (CDC)?
Change Data Capture (CDC) is a design pattern for continuously identifying inserts, updates, and deletes in a source system and propagating only those changes downstream.
Compared to batch ETL, CDC reduces latency, minimizes load on source systems, and enables real-time analytics and event-driven architectures. Modern implementations typically use log-based approaches that read database transaction logs for low overhead and full fidelity.
CDC is what makes “near real time” actually reliable, because you are capturing committed changes at the source.
Why CDC is important today
Your company’s data is always changing. A user updates their profile, an order is amended, or a subscription is canceled.
If analytics, automations, and customer touchpoints lag hours behind, you’re making decisions on stale data.
Change Data Capture (CDC) helps close that gap by:
- Streaming only what changed instead of entire tables
- Keeping dashboards and reports up to date
- Reducing load on primary systems
- Creating a reliable history of data changes
- Letting downstream systems react faster
Instead of relying on heavy nightly data jobs, CDC shifts you toward smaller, incremental data flows that stay continuously in sync as your data grows.
The point of CDC is not “streaming for streaming’s sake.” It’s making sure your decisions aren’t driven by stale state.
What CDC actually is (and isn’t)
From our perspective at Weld, one important caveat is that not every team should rush to adopt CDC.
If your datasets are small, change slowly, or your systems can tolerate a few hours of delay, then traditional batch processes may be simpler and more cost-effective.
CDC is not a single product. It’s an architectural approach that can be implemented in different ways, but the outcome is always the same. Capture changes at the row level and move them downstream in a reliable and consistent fashion.
Many databases and platforms expose CDC natively. Others rely on connectors that read the database’s transaction log or use triggers.
In short, CDC continuously captures inserts, updates, and deletes from a source system and delivers them to downstream systems so they can stay in sync in near real time.
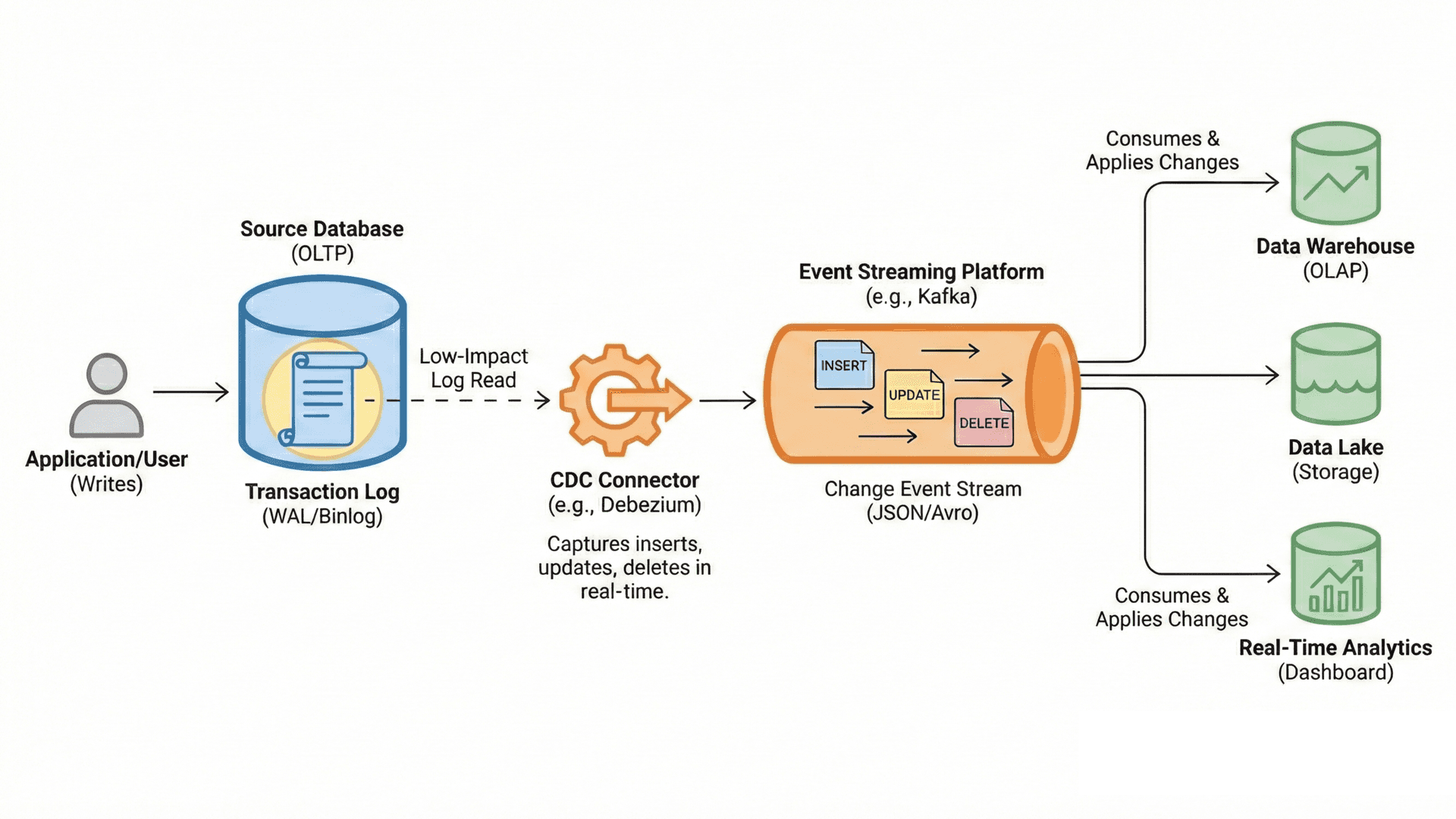
How CDC works: core patterns and trade-offs
Here are the main approaches we see in practice, along with examples.
Timestamp or version polling queries rows where last_modified > last_sync. It’s simple to set up, but in one SaaS dataset we looked at, this method missed deletes entirely, which led to inconsistencies.
Snapshot diffs take full or partitioned snapshots and compare them. This can work universally, but we’ve seen teams struggle with rising costs when table sizes grow into the billions of rows.
Database triggers write changes to an outbox or change table. This ensures inserts, updates, and deletes are captured, but a fintech team we spoke with experienced latency spikes because every write fired additional logic.
Log-based CDC reads directly from transaction logs like Postgres WAL or the MySQL binlog. This is the gold standard today. It captures every change with strong ordering guarantees and little extra strain. In our internal testing with Postgres, log-based CDC has consistently kept replication lag low and stable.
Among these approaches, log-based CDC has become the standard for production systems because it captures every change with strong ordering guarantees while putting little additional strain on the source database.
If you need correctness, ordering, and deletes, log-based CDC is usually the shortest path to “it just works.”
CDC vs incremental sync vs full table sync
Not every use case requires full CDC. The table below compares common sync approaches.
| Approach | How it works | Captures deletes | Low latency | Low source load | Best fit |
|---|---|---|---|---|---|
| Full table sync | Re-copy entire tables on a schedule | ❌ | ❌ | ❌ | Small datasets |
| Incremental sync | Pull rows using timestamps or IDs | ⚠️ | ⚠️ | ✅ | Moderate freshness needs |
| Change Data Capture (CDC) | Stream changes from database logs | ✅ | ✅ | ✅ | Real-time systems |
The CDC pipeline, end to end
A typical CDC pipeline starts with an initial snapshot to provide downstream systems with a baseline.
Once that snapshot is complete, the system begins capturing new changes as they happen. These changes are transported through a message bus or directly into the warehouse.
Along the way, they may be filtered, enriched, or deduplicated before being applied as upserts or deletes. To ensure reliability, offsets and checkpoints are stored for recovery.
Finally, observability is essential. Monitoring lag, throughput, and error rates ensures pipelines run smoothly, even as schemas evolve.
CDC pipelines do not usually fail loudly. Good observability is what stops silent data drift.
Where CDC shines and where it’s overkill
CDC is an excellent fit for scenarios where fresh data truly matters. Real-time analytics, customer 360 projects, and compliance use cases all benefit from data that reflects operational reality within seconds or minutes. It’s also a powerful enabler for event-driven architectures and microservices.
But CDC isn’t necessary everywhere. For small, slowly changing datasets, nightly batch updates may be more than enough. In legacy systems where you can’t access logs or add triggers, implementing CDC may be too costly compared to the benefits.
CDC vs ETL vs app events
It’s important to understand what CDC is, and isn’t, in relation to other approaches.
Traditional ETL pipelines move bulk data on a schedule, often requiring heavy merges to stay current.
CDC continuously streams only the changes, reducing the load and improving freshness.
Application events are useful for specific workflows, but they don’t always provide a complete picture of state.
Because CDC is rooted in the database itself, it's a reliable source of truth. In many modern data stacks, CDC and ETL coexist, each serving different needs.
From our experience at Weld, there are cases where teams think they need CDC but actually don’t. If the only requirement is to refresh a dashboard every few hours, implementing CDC might add unnecessary complexity without meaningful benefit.
Tooling landscape
The CDC ecosystem is broad, with options for every type of workflow.
Open-source tools like Debezium and Kafka Connect provide log-based CDC connectors for popular databases.
Managed cloud services like AWS DMS, Google Cloud Datastream, and Azure Data Factory can run CDC pipelines without you operating the underlying infrastructure.
Commercial platforms offer turnkey connectors, monitoring, and enterprise-grade support. Teams often use platforms like Weld when they want log-based CDC into the warehouse with minimal operational overhead.
On the destination side, most modern warehouses support efficient upserts and deletes. Snowflake, BigQuery, Redshift, Databricks, and ClickHouse are all common targets for CDC-style pipelines.
When choosing a CDC tool, consider:
- Which databases and platforms it supports
- How it handles schema changes and backfills
- The delivery guarantees it provides
- What monitoring and observability features are included
Warehouses and CDC application patterns
Most warehouses apply CDC streams using a small set of repeatable patterns.
Snowflake commonly applies changes using MERGE into a target table. Some teams also use Streams and Tasks for CDC-like processing once data is already landed. Read the Snowflake MERGE docs here →
BigQuery typically applies CDC via MERGE. A common approach is to stage changes into a delta table and merge into curated models on a schedule that matches freshness requirements. Read the BigQuery MERGE docs here →
Amazon Redshift supports MERGE for applying updates and deletes. Teams often combine staging tables with compaction and vacuum strategies to keep performance stable. Read the Redshift MERGE docs here →
Databricks (Delta Lake) often applies CDC using MERGE INTO on Delta tables. This fits well when changes land in object storage and are processed with structured streaming or micro-batches. Read the Delta Lake MERGE docs here →
ClickHouse is often handled with append-first ingestion plus deduplication using table engines or materialized views. Updates and deletes usually require an explicit strategy for late-arriving changes. Read the ClickHouse docs here →
Popular CDC tools (and when to use them)
This section is not a “best tools” list. It’s a practical map of tools teams commonly pick depending on architecture and operating model.
Commercial platforms
Weld
Best for: Log-based CDC into your warehouse with minimal operational overhead and strong observability.
Not ideal if: You need a Kafka-first topology and prefer to build everything as streaming primitives.
Read our CDC documentation here →
Fivetran
Best for: Managed ingestion where CDC is one of several connector needs.
Not ideal if: You need fine-grained control over streaming semantics or custom routing.
Read the Fivetran docs here →
Qlik Replicate / Qlik Data Streaming
Best for: Enterprise replication with broad connectivity and vendor support.
Not ideal if: You prefer open-source components and custom pipelines.
Read the Qlik Replicate overview here →
Striim
Best for: Real-time integration that combines CDC with in-stream processing and many delivery targets.
Not ideal if: You only need basic warehouse ingestion and want minimal platform surface area.
Read the Striim overview here →
Oracle GoldenGate
Best for: Oracle-heavy environments that need robust replication at scale.
Not ideal if: You want a simpler, lower-cost setup for a small number of sources.
Read the GoldenGate overview here →
Managed cloud services
AWS Database Migration Service (AWS DMS)
Best for: Managed CDC on AWS for migrations or ongoing replication into AWS destinations.
Not ideal if: You need complex routing, deep transformations, or strong non-AWS integration.
Read the AWS DMS CDC docs here →
Google Cloud Datastream
Best for: Managed CDC in GCP with a straightforward replication path.
Not ideal if: Your orchestration and targets live mostly outside Google Cloud.
Read the Datastream overview here →
Azure Data Factory
Best for: Teams standardized on Azure tooling and governance.
Not ideal if: You want a CDC setup that stays close to logs with minimal orchestration overhead.
Read the ADF CDC docs here →
Open-source building blocks
Debezium
Best for: Log-based CDC with full control when Kafka is already part of the stack (or will be).
Not ideal if: Your team does not want to operate streaming infrastructure.
Read the Debezium docs here →
Kafka Connect
Best for: Standardized connector operations when Kafka is already your backbone.
Not ideal if: Kafka is not part of your stack and you are trying to stay lightweight.
Read the Kafka Connect docs here →
Airbyte
Best for: UI-driven ELT with CDC for a subset of supported databases.
Not ideal if: You need strict low-latency guarantees across many sources and targets.
Read the Airbyte docs here →
Estuary Flow
Best for: Managed streaming with continuous delivery and low-latency targets.
Not ideal if: You need a pure self-hosted option with full control of runtime.
Read the Estuary Flow overview here →
A simple checklist for choosing a CDC tool
Use this as a quick filter before doing deeper evaluation.
Source access
Can you read the transaction log safely and with the right permissions? If not, you may be pushed toward polling, triggers, or a managed service that fits your environment.
Deletes and ordering
Do you need accurate deletes and consistent ordering guarantees? If yes, prefer log-based CDC.
Operational overhead
Who will run it? If nobody wants to operate streaming infrastructure, a managed service or a platform like Weld is usually the better fit.
Schema changes and backfills
How often do schemas evolve, and how painful are backfills? Choose tooling that makes these routine, not heroic.
Target and delivery model
Are you delivering to Kafka, a warehouse, object storage, or operational systems? Pick tooling that is strongest for your primary target.
How CDC works in Weld
Weld’s CDC connectors are designed to bring real-time database changes into your data warehouse with minimal operational overhead. Rather than scanning tables or relying on timestamp-based syncs, Weld reads directly from database logs, the source of truth for all committed transactions.
The diagram below illustrates how Weld CDC captures row-level changes from your operational databases, adds metadata for tracking, and keeps your data warehouse perfectly aligned in real time.
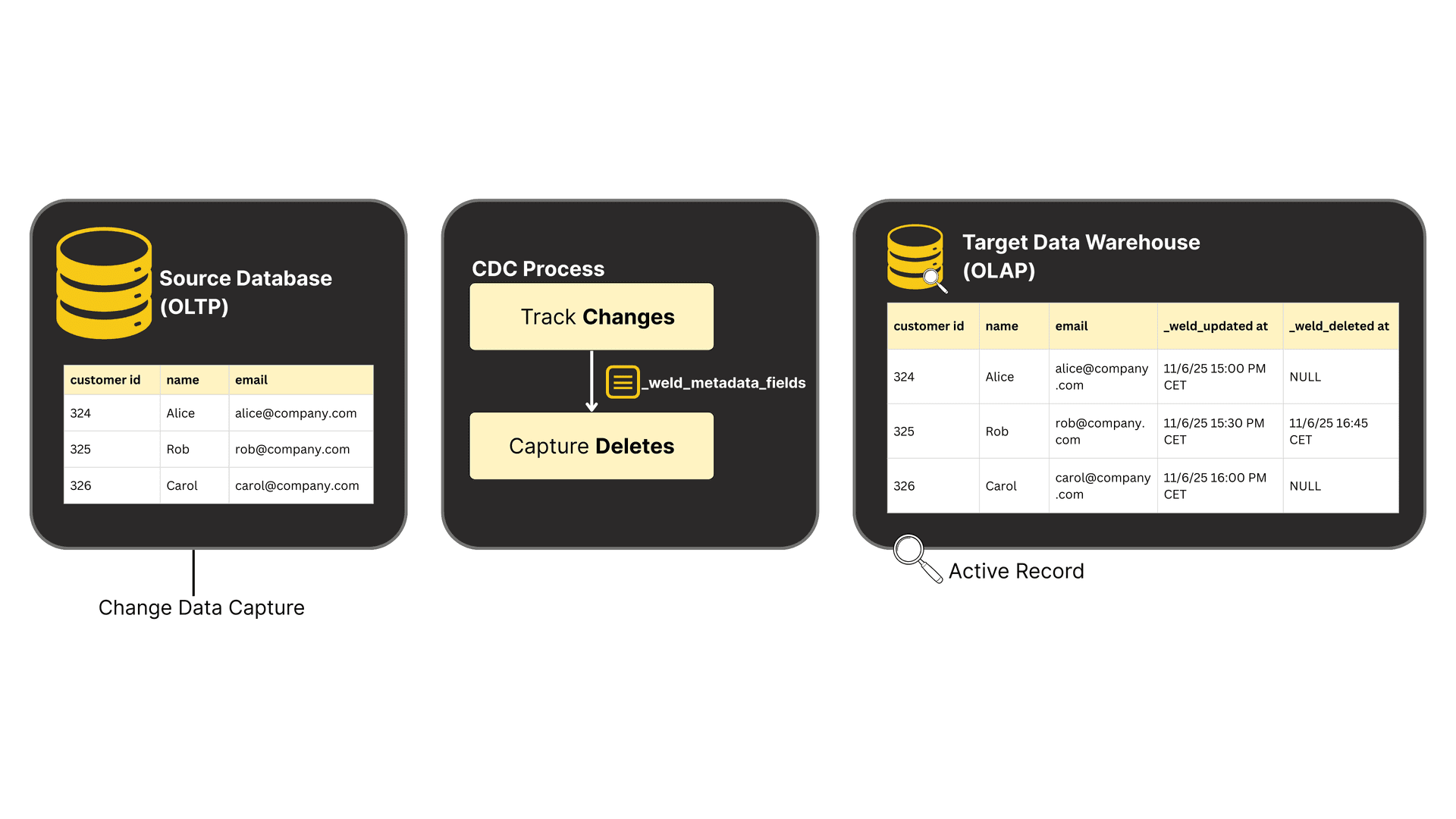
Figure: Weld’s CDC flow captures inserts, updates, and deletes directly from the source database, enriches them with metadata fields like _weld_updated_at and _weld_deleted_at, and keeps your warehouse tables continuously in sync, without manual snapshots or merges.
Weld gives us the ability to see a huge array of KPIs and data points that we can then feed back to clients in an insightful and actionable way.
MySQL CDC
Weld’s MySQL CDC connector streams row-level inserts, updates, and deletes by reading from MySQL’s binary log (binlog) through a replication connection. This approach delivers lower latency, reduces read pressure on the primary, and reliably captures deletes. Weld consumes row-based events from the binlog and applies them downstream in near real time.
To enable this, MySQL must have binary logging turned on and configured for row-based capture. Typical prerequisites include log_bin=ON, binlog_format=ROW, binlog_row_image=FULL, a unique server_id, and a retention window. binlog_expire_logs_seconds=604800 is a common default to start with.
Each CDC table must have a primary key or unique index to ensure updates and deletes are applied correctly.
For more details on MySQL CDC visit our documentation on our website here →.
PostgreSQL CDC
Weld’s PostgreSQL CDC connector streams row-level changes by reading from PostgreSQL’s Write-Ahead Log (WAL) using logical replication. Changes are captured via a replication slot and a publication that determines which tables are included.
To enable this, PostgreSQL must support logical replication (for example wal_level=logical), and you’ll configure a replication slot and publication for the tables you want to capture. Tables should have a primary key or unique index so updates and deletes can be applied correctly downstream.
For more details on PostgreSQL CDC visit our documentation here →.
Microsoft SQL Server CDC
Weld’s Microsoft SQL Server CDC connector streams changes using SQL Server’s transaction log-based change capture capabilities (depending on environment and configuration). This approach captures inserts, updates, and deletes with low latency and avoids repeated table scans.
To enable this, you’ll typically ensure the required CDC features/permissions are available, create a user for Weld with the necessary access, and select the tables to capture. As with other CDC approaches, having stable identifiers (primary keys) is important for correct downstream application of updates and deletes.
For more details on SQL Server CDC visit our documentation here →.
MongoDB CDC
Weld’s MongoDB CDC connector streams document-level inserts, updates, and deletes using MongoDB’s native change streams. This provides a continuous feed of changes so downstream systems can stay in sync with low latency.
To enable this, you’ll configure connectivity and a MongoDB user with the required permissions, then select which databases/collections to capture. MongoDB’s _id typically provides the stable identifier needed to apply updates and deletes correctly downstream.
For more details on MongoDB CDC visit our documentation here →.
Best practices
Start small, with a single high-value domain, and expand gradually.
Favor log-based CDC where possible, since it offers the most reliable coverage with the least overhead.
Make sure downstream logic is idempotent so it can handle retries. Build transformations that are aware of schema versions and document ownership of each pipeline. Finally, separate backfills from live streams to protect latency and reliability.
Where Weld fits today
Weld is built for modern data teams that want high-quality, timely data without brittle jobs. Today, customers use Weld to ingest from databases and SaaS tools, model that data with SQL, orchestrate reliable pipelines, and activate fresh data back into business tools. This foundation makes CDC-style workflows easier to adopt because the downstream modeling, orchestration, and activation are already solved.
The best CDC pipeline is the one you can operate confidently month after month, even as schemas and volume change.
FAQs
Choosing CDC
Does CDC replace ETL?
Not usually. CDC and batch ETL are complementary:
- Use CDC for continuous freshness (inserts/updates/deletes) and low-latency sync.
- Use batch ETL for initial loads, backfills, historical rebuilds, and recomputing derived models.
A common setup is: snapshot/backfill first, then CDC keeps tables current.
Is CDC always the right choice?
No. CDC adds operational complexity. If your data changes slowly, tables are small, or hourly/daily updates are fine, scheduled syncs can be simpler and cheaper.
What latency should I expect?
CDC is typically seconds to minutes, but depends on:
- source write volume,
- network,
- destination apply strategy (per-event vs micro-batch),
- warehouse compute and merge/apply cost.
Data correctness
Do I need primary keys (or unique IDs) for CDC?
For reliable updates/deletes, yes.
- Relational tables should have a primary key (or stable unique key).
- MongoDB typically uses
_id.
Without a stable identifier, downstream systems can’t safely apply updates/deletes to the correct record.
Will CDC capture deletes?
With true CDC (log/stream-based), yes. How deletes appear downstream depends on your destination strategy (hard deletes vs soft deletes).
How do schema changes work with CDC?
Commonly supported: adding columns.
Harder cases: renames/drops/type changes often require coordination and sometimes a backfill. Treat schema evolution as a planned workflow.
Warehouses and apply patterns
How do warehouses apply CDC?
Most destinations apply CDC using one of these patterns:
- Stage → MERGE: land change events in a staging/delta table, then
MERGEinto the target table. - Micro-batch apply: accumulate changes briefly and apply in batches (often better cost/perf).
- Soft delete: represent deletes via a deleted flag/timestamp when physical deletes aren’t desired.
Operations and monitoring
Does CDC impact my production database?
CDC avoids table scans, but it’s not free:
- It reads from a database’s log/stream and may require retaining logs long enough for the consumer to keep up.
- If the consumer falls behind or a CDC reader is abandoned, log retention can grow (WAL/binlog/etc.).
What should I monitor?
At minimum:
- Replication/apply lag
- Error rate / retries
- Log retention pressure (WAL/binlog/oplog growth)
- Destination merge/apply duration Also watch schema changes and backfills, which can spike load.
What happens if Weld goes down or the connection drops?
CDC pipelines typically resume from the last stored position (offset/checkpoint). If the source retention window is exceeded while offline, a resnapshot/backfill may be required.
Can I backfill without breaking CDC?
Yes. Treat backfills as a controlled operation:
- Prefer staging/backfill tables and swap/merge strategies
- Expect higher destination apply cost during large backfills
- Keep CDC running where possible
Database-specific
How does PostgreSQL CDC work?
PostgreSQL CDC is typically WAL-based logical replication, using a replication slot and a publication to define which tables to capture.
See: PostgreSQL CDC
How does MySQL CDC work?
MySQL CDC is typically binlog-based, streaming row changes via a replication connection (commonly binlog_format=ROW).
See: MySQL CDC
How does Microsoft SQL Server CDC work?
SQL Server provides native CDC that reads the transaction log and writes changes into CDC tables for enabled tables.
See: Microsoft SQL Server CDC
How does MongoDB CDC work?
MongoDB CDC is typically implemented using Change Streams, which emit document-level change events.
See: MongoDB CDC
Sources
- Databricks: What is change data capture? →
- IBM: Change Data Capture →
- Datacamp: Change Data Capture →
- Microsoft Learn: About change data capture (SQL Server) →
- Debezium documentation →
- AWS DMS CDC docs →
- Google Cloud Datastream overview →
- Azure Data Factory CDC docs →
- Snowflake MERGE docs →
- BigQuery MERGE docs →
- Amazon Redshift MERGE docs →
- Databricks Delta Lake MERGE docs →
- ClickHouse documentation →