

Depending on where your company stands in its data journey, you may or may not be familiar with reverse-ETL. While many organizations have managed to centralize their data in a data warehouse, figuring out what to do with that data is a common challenge. Beyond standard visualizations and reporting, it can feel like something’s missing from your data operations—like there’s a secret to becoming data-driven that needs to be unlocked.
Wonder no more, the secret to data-driven business is reverse-ETL.
In recent years, Snowflake, Google BigQuery, Amazon Redshift, and other data warehouses have rapidly become the central nervous system of businesses. Bringing all your insights into one secure, organized location is essential—but too often, data efforts stop there. Reverse-ETL is the missing piece of data activation, and modern tools can make this a reality at your company.
Keep reading to learn how reverse-ETL brings your data out of the warehouse and into your daily operations. Plus, we’ll cover examples of reverse-ETL in action and how to select the right tool for your needs.
Defining Reverse-ETL
Simply put, reverse-ETL consists of the connectors that extract data from your data warehouse and deliver it into the tools, apps, and other destinations your teams use every day. To clarify further, let’s review some basics.
What is ETL, or ELT?
Before diving into reverse-ETL, it’s important to understand ETL. ETL stands for Extract, Transform, Load and is also known as ELT because, in many modern data setups, the process is done in the order of Extract, Load, Transform.
ELT is the process of taking data from a system of record—such as an app like Hubspot or a database like PostgreSQL—and copying it into a data warehouse through pipelines built by data engineers to extract the right data from various sources.
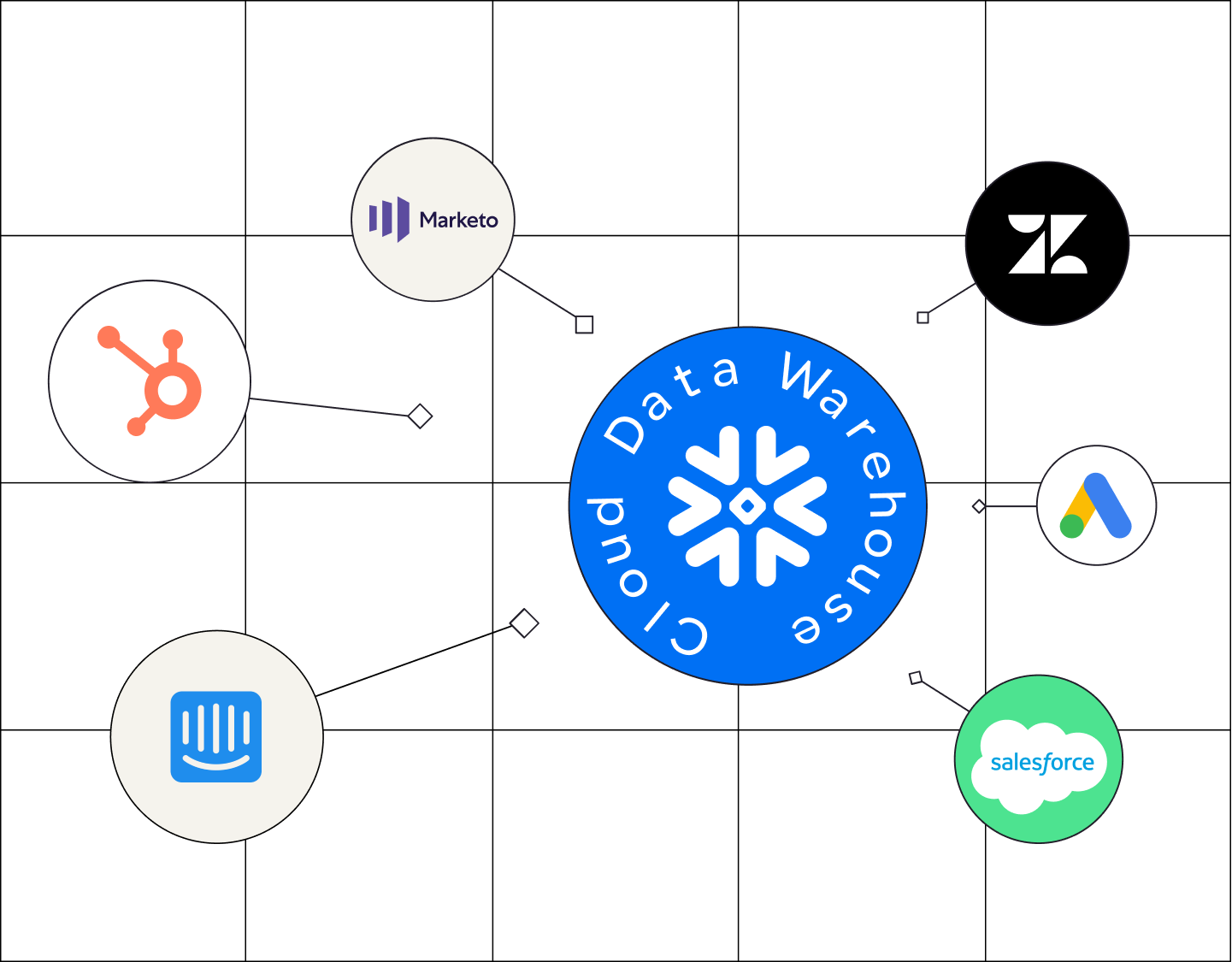
What is a Modern Data Stack?
It's easier to grasp ETL when you’re familiar with the concept of a modern data stack. A modern data stack is the collection of tools that manage your data, usually comprising six components: sourcing, ingestion, storage, modeling, visualization, and activation. It transforms data from dispersed, unstructured, and unusable to centralized, organized, and actionable.
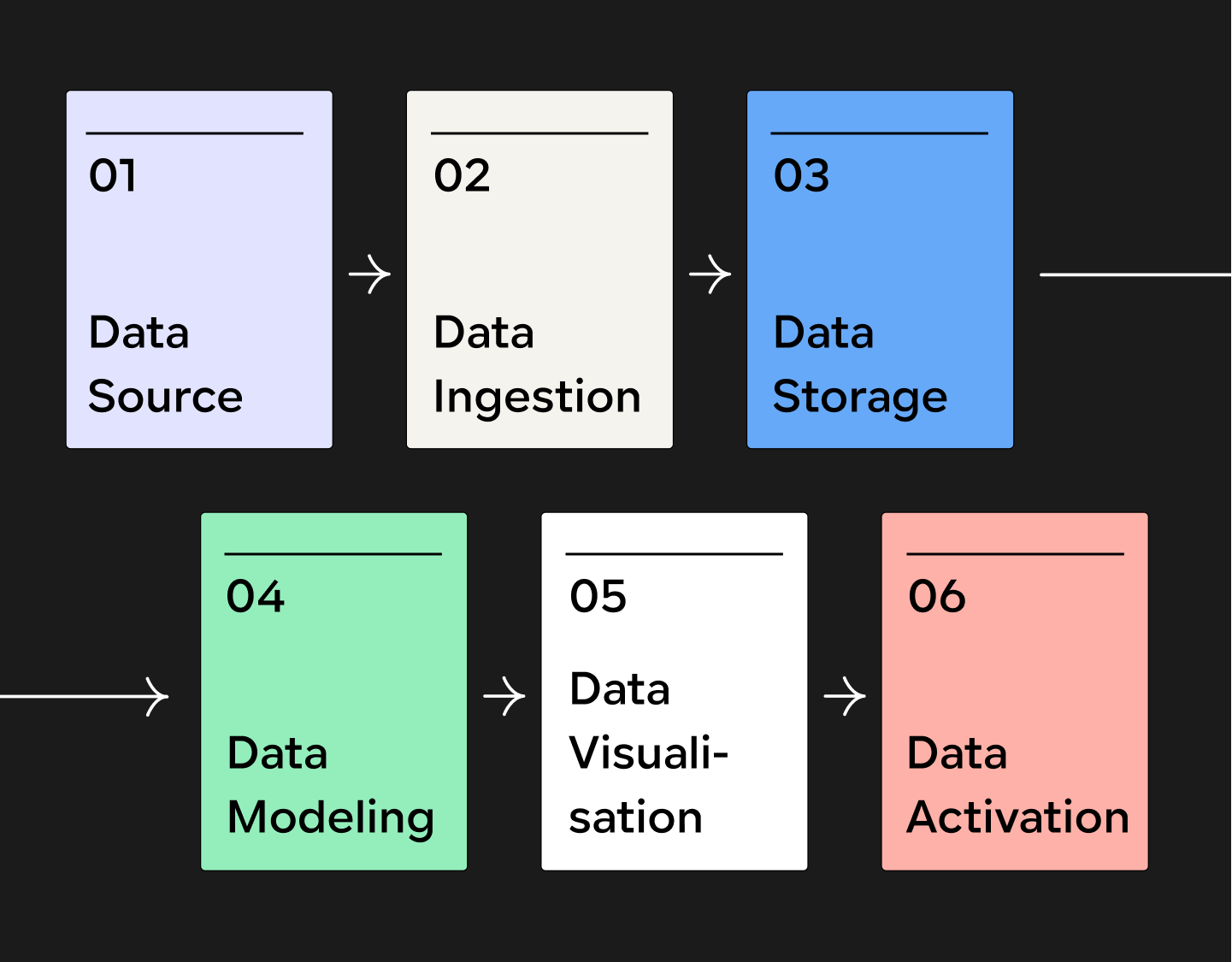
ELT pipelines are part of the ingestion phase: your ELT connectors move your data from the source to the data warehouse and transform it into a usable state.
What is Reverse-ETL?
With all that context, reverse-ETL is essentially the opposite of ETL. It’s the process of moving your data back out of your data warehouse and into the tools and apps your teams use every day. However, this happens after the data has been centralized, cleaned, and structured—making reverse-ETL the key to data activation.
With reverse-ETL, you can sync your core business metrics like CAC, LTV, and Health Score into all your tools, integrating data into every team’s daily operations. Reverse-ETL is arguably the most important step in a modern data stack and is essential for achieving data-driven success.
What are the use cases for reverse-ETL?
Reverse-ETL offers numerous benefits. Teams no longer have to hunt for the data they need to make decisions—the data is already present in the software and tools where they work. This also simplifies creating and maintaining KPI alignment across teams, ensuring everyone uses the same business definitions for core metrics.
But more concretely, what does reverse-ETL look like in action? Here are three main use cases and real-life examples:
1. Data Automation for Streamlined Workflows
Reverse-ETL enables data automation to build more efficient, streamlined workflows. In essence, it feeds key data points and metrics into operational systems at a predefined frequency. This data can then automate various workflows within the system it’s pushed to.
For example:
If your company’s CRM is Hubspot and your sales and customer success teams rely on it daily, reverse-ETL can take product data from your warehouse, push it to Hubspot, and create alerts so that account managers are notified when a freemium account reaches a specific threshold in the sales funnel. This minimizes platform switching and ensures no opportunities are missed.
2. Breaking Down Data Silos Across Teams
Data silos are a common barrier to high performance and alignment. When crucial customer data is split among different tools, teams may work with differing or incomplete information. Even a well-implemented data warehouse can become a silo if the data isn’t actively shared.
With reverse-ETL, your core business metrics aren’t confined to the data warehouse; they’re pushed to every team’s tools. For instance, a marketer using Customer.io, a support agent using Zendesk, and an account manager using Salesforce can all see the same accurate, up-to-date health score metrics for their customers.
3. Enabling More Efficient, Impactful Work
When teams spend excessive time manually searching for data, they’re unable to focus on high-impact work. Reverse-ETL frees up teams to concentrate on their core responsibilities. Here’s how:
- Data teams spend less time building and managing pipelines manually and more time creating models that benefit the organization.
- Sales teams no longer have to toggle between multiple tabs to find customer data, as it’s consolidated within their CRM.
- Support teams get incoming tickets automatically sorted by priority based on the health score metric.
- Marketing teams can launch hyper-targeted email campaigns using metrics like CAC, Health Score, or MRR for segmentation.
What to Look for in a Reverse-ETL Tool
Although reverse-ETL is crucial for a data-driven business, not all reverse-ETL tools are created equal. Consider these key factors when selecting a reverse-ETL tool:
Reliable Syncing is a Must
Syncing is arguably the most critical function of a reverse-ETL tool—it keeps all your data aligned in real time. If syncing fails, teams may work with outdated or incorrect data. Ensure the tool you choose prioritizes reliable, consistent syncing.
The Latest in Security Technology and Regulations
Reverse-ETL tools handle sensitive data, so robust security and privacy are essential. As digital literacy and regulatory requirements grow, your tool must protect data to avoid breaches, fees, or penalties.
Integrations with the Tools You Use
Make sure the reverse-ETL tool you choose integrates with the apps and systems your teams already use. Most solutions list their supported integrations; verify that the tools you rely on are included.
Leverage Data with Weld's Cutting-Edge Reverse-ETL
Built by engineers, Weld’s reverse-ETL connectors help companies of all sizes bring data into their daily operations. Weld is a comprehensive solution that sits atop your data warehouse to handle all aspects of a modern data stack. If you’re looking for a tool that can source, extract, transform, and activate your company data, why not give Weld a try or chat with one of our experts to see how Weld can power your teams.
















