
Data pipeline
A data pipeline is a combination of data processes that move data from a source system to a target destination, usually through ELT or reverse-ETL.
What is a data pipeline?
A data pipeline is an automated system that moves data from one place to another. Data pipelines are essentially a series of steps to process and sometimes transform data. They’re made up of 3 key things:
- A data source
- Data processes
- A target destination
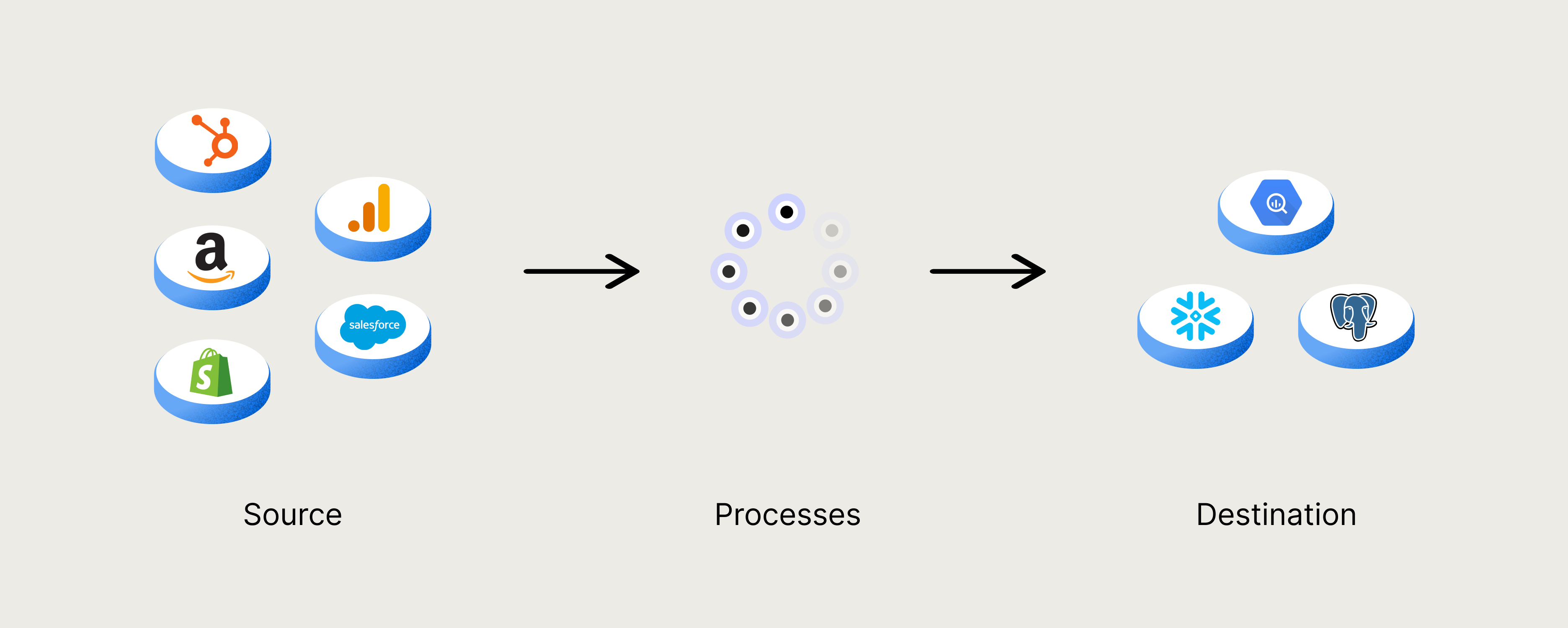
Data pipelines are a crucial part of business data operations. These pipelines are the channels through which data is taken from a source and copied to a target destination, making it usable.
ETL/ELT data pipelines
One of the most common types of data pipelines are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines. These pipelines bring data from various sources into your data warehouse, centralizing your data for analysis and activation. This is the first step in most companies’ data operations, and key to making use of customer data.
Reverse-ETL data pipelines
Another common type of data pipeline is reverse-ETL pipelines. These pipelines send data from your data warehouse out to other destinations, like your data visualization tools, SaaS apps, and reporting dashboards. Reverse-ETL is a common method of activating customer data, and embedding it into the day-to-day functioning of your business.
Custom vs. pre-built data pipelines
Many data teams build their own data pipelines to stream data in and out of their data warehouse. While this might work for very small-scale data operations, it’s not usually a scalable solution as custom-built data pipelines require a fair amount of maintenance. As your data team grows and more people are working on more pipelines, the manual workload of building and troubleshooting your data pipelines will quickly take up the majority of your team’s time.
In the era of the modern data stack, several tools have been developed with pre-built, no-code data pipelines you can use for your data operations. This is a great step forward, but even with the best ELT and reverse-ETL tools, you may still run into challenges. When you’re splitting up your ELT, reverse-ETL, data modelling, and other core data operations between various software, it can lead to inefficiencies and additional maintenance work. This is why many data teams are opting to buy rather than build a modern data stack.
Dozens of pre-built data pipelines in Weld
If you’re looking for a scalable solution to get your data pipelines up and running quickly and without the need for ongoing maintenance, Weld could be the right option for you. With dozens of pre-built ELT and reverse-ETL pipelines and a best-in-class data modelling tool, Weld centralizes your core data tasks in a single platform. Curious to learn more about how Weld can power your data operations? Book a call with one of our data specialists.